

here's a crazy cool thing we built
here's a crazy cool thing we built
search the startupy hivemind 👀
Instead of a regular issue, here's a crazy great thing we built this week:
startupy.world/ask
It's an AI-powered search engine of the startupy hivemind.
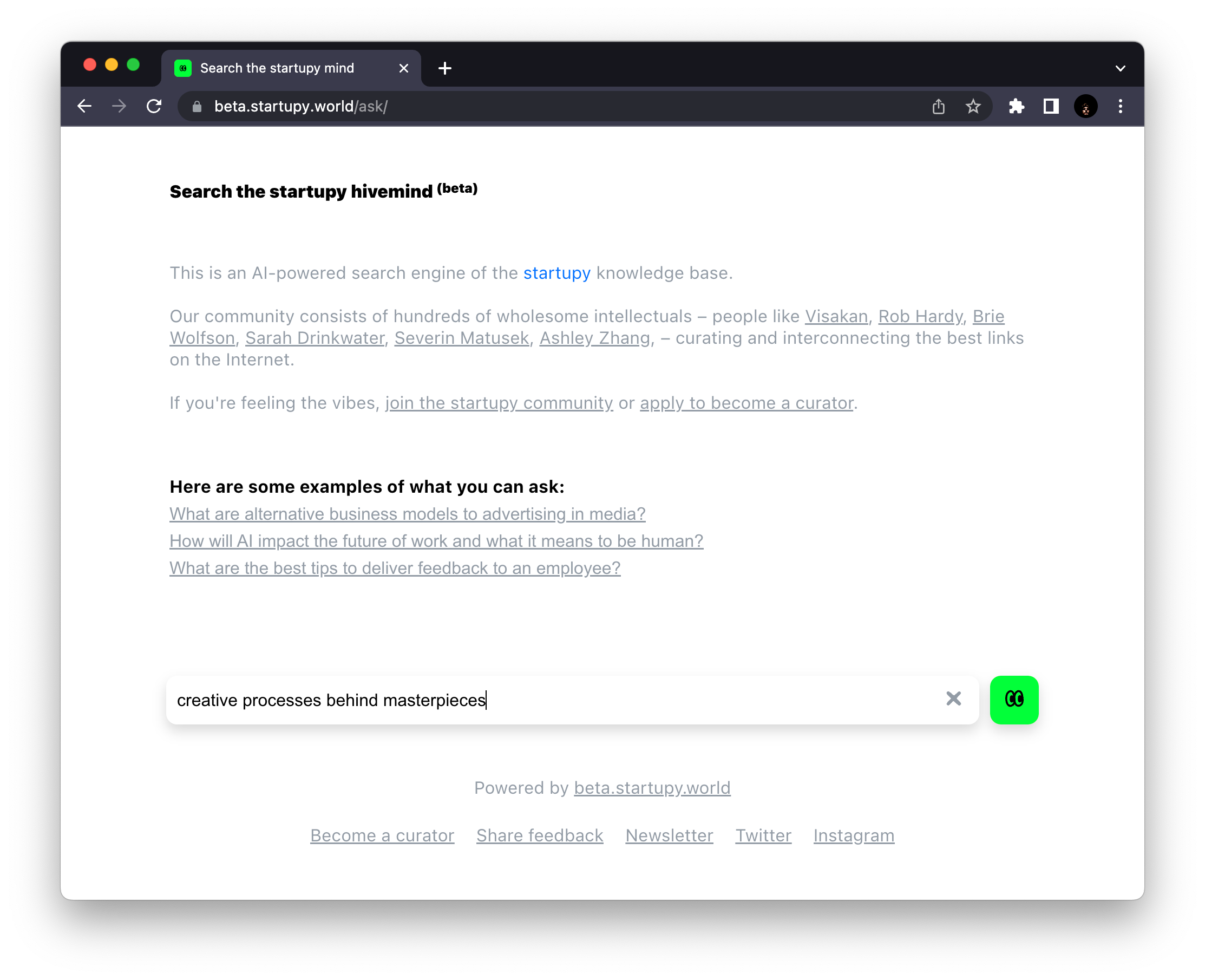
Type any abstract question or phrase and it will semantically search over everything the startupy community has ever curated and return relevant quotes.
I’m biased, but I think this is one of the few places on the Internet where you can search across a highly curated corpus of evergreen and platform agnostic articles, videos, podcasts, tweets, etc… and get the good human stuff, zero SEO manufactured garbage.
Try it out! And if you find it valuable please please share it. We are trying to build this corner of the Internet one human at a time.
If you’re interested in the behind the scenes thinking that went into this, keep reading. I’m going to toss a few streams of consciousness thoughts and questions I’ve been mulling over as I try to make sense of AI, LLMs, and the evolving world of online search. And if there’s anything else you want to know, ask away in the comments!
I’ve written in the past about the need for boutique search engines. Google is a great example of how the internet enables scale and speed: every page on the web returned in an instant. Open AI is the same – it’s trained on the entirety of the web, both the good and bad. If you’ve used chatGPT, you’ve probably experienced this scale being at odds with a fundamental human need: relevance, taste, intentionality.
The answers of AI search engines are only as good as the information they can access, which is why I’m most excited about using LLMs trained on curated datasets. Algorithms have their limits; so do humans. I think the magic is when human taste works in harmony with technology - artisanal automation, if you will.
I’ve seen lots of tools that leverage LLMs to summarize an article, a video whatever. I can see how that’s helpful in helping you decide whether to read something, but I also think it removes some of the “magic”. The best moments on the Internet happen when you come across the perfect words articulated by a stranger. The fact that the words are human and authentic is what makes them valuable. So instead of building a chatbot, we focused on using embeddings to return semantically similar quotes. This keeps it profoundly human.
One question I keep returning to is what impact LLMs will have on tags and categorization. I’ve lost years of my life tagging content, and yet this search engine doesn’t need tags or categories to be useful. Is this the end of organizing? I’ve been approaching this question with an open mind, and here’s what I believe to be true:
Human tagging is messy and suboptimal for many reasons. First, it’s impossible to categorize things in all of the ways you or other people might want to recall them later. Second, ontologies evolve. What we call “design” a few years later evolves to “web design”, then “UX design”, and on and on… Thirs, different people may use different labels to refer to the same thing. I may tag something #Mac and you tag it #Apple. In some cases we can reasonably assume that we’re talking about the same thing and find ways to merge them, but as the boundaries get porous - think Web 3 and crypto, or movies and cinema - there is some signal loss that results from erasing the difference of expression. Third, tags are often abandoned and poorly maintained. You may tag some things #sciencefiction then forget you have the tag and add a bunch of stuff related to science fiction without the tag, at which point search becomes more effective.
A semantic search engine is extremely powerful, but I think a search box and millions of articles is the wrong UI in many cases. It puts all the burden on the user to articulate good questions instead of letting people incrementally explore in a variety of ways. Search interfaces help you find what you are looking for. But they don’t help you find the things you didn’t know you were looking for.
Related to the point above, I think there is a lost art to having the right things near each other. What’s the point of organizing things in your Google Drive folder when you can find them faster using the search bar? I like this framing:

Even if machines can do a lot of the classifying, drawing associations between things in a way that feels personal is still a deeply satisfying muscle worth exercising. When you have a concept or theme in mind, what you have is a mental bucket, a magnet for anything that relates to the subject of your obsession. An obsession, in that sense, is a hell of a useful thing for the mind. Our interfaces have been feeding us, but don’t allow for any digesting. In that sense, curating, collecting, and listmaking help us turn the web from a place of mindless consumption to a place for mindful sensemaking.
Tagging an article #philosophy is low value work that can and should be done by machines. But I think there is a difference between tags for generic topics or keywords and more meaning and taste rich concepts. For example: Good questions, Social media is too fast, Building with soul, How I want to teach my kids, What does it mean to be human. Deciding what can and should belong in these collections requires human taste, judgment, and the ability to integrate knowledge in unique ways.
All in all I think classification and organization beyond a search box is still important. A lot of it can and should be done by machines. But the magic of being able to peak inside someone’s brain, to watch them draw connections amongst seemingly unrelated things is not only a muscle worth exercising, but a beautifully human and useful way to navigate information and encourage lateral discovery.
A technical questions I’m still pondering: How can semantic search coexist with keyword search? What are the best practices here? If you have insights, I’d love to hear them.

Ok, that’s that.
If you made it this far and have been a regular reader of this newsletter (or my personal newsletter before this), I also built a search engine for my mind, which you can try here.
Stay human, friends.
Sari
Want to find us elsewhere?
☼ Twitter
☼ Instagram
☼ Spotify
☼ Startupy
STOP - DO NOT INVEST IN SUBSTACK'S BROKEN MODEL!!!
Seriously if they are begging for money and VC bailed it means its a broken model. Think about it, how many regular people are paying per writer $5 to $10 per month? Not enough apparently and the next thing they will introduce is advertising which is 1million times worse. This monetization model is for elites, elite writers and elite readers who can afford to pay to "benefit" from their writing. Its not Twitter but its just as elitist as Twitter and will devolve into the same mess and control mechanism.
Go check out web3. Go check out crypto. Go check out the MVP of my solo hobbiest project "dplatform.me" The next platforms will be web3, crypto, micro-transactions, and governed by decentralized autonomous organizations (DAOs) or no one
The future is decentralized!
How did you build the search engine for your mind? It’s so cool! I’d love to use my second brain data and try to build one myself